Преобразование голоса при отсутствии параллельных данных
Субтитр: Говорить как Кейт Уинслет
Авторы: Даби Ан (andabi412@gmail.com), Кьюбён Парк (kbpark.linguist@gmail.com)
Образцы
https://soundcloud.com/andabi/sets/voice-style-transfer-to-kate-winslet-with-deep-neural-networks
Введение
Что, если бы вы могли имитировать голос известной знаменитости или петь, как известный певец?
Этот проект начался с целью преобразования чьего-либо голоса в конкретный целевой голос.
Так называемый перенос стиля голоса.
Мы работали над этим проектом, цель которого — преобразовать чей-то голос в голос знаменитой английской актрисы Кейт Уинслет.
Для этого мы внедрили глубокие нейронные сети и использовали более 2 часов аудиозаписей предложений из аудиокниг, прочитанных Кейт Уинслет, в качестве набора данных.

Архитектура модели
Это система преобразования голоса «многие к одному».
Основная значимость этой работы заключается в том, что мы смогли генерировать высказывания целевого говорящего без параллельных данных типа <исходный wav, целевой wav>, <wav, текст> или <wav, телефон>, а только с использованием волновых форм целевого говорящего.
(Создание этих параллельных наборов данных требует больших усилий.)
Всё, что нам нужно в этом проекте, — это несколько волновых форм высказываний целевого говорящего и небольшой набор пар <wav, телефон> от нескольких анонимных говорящих.
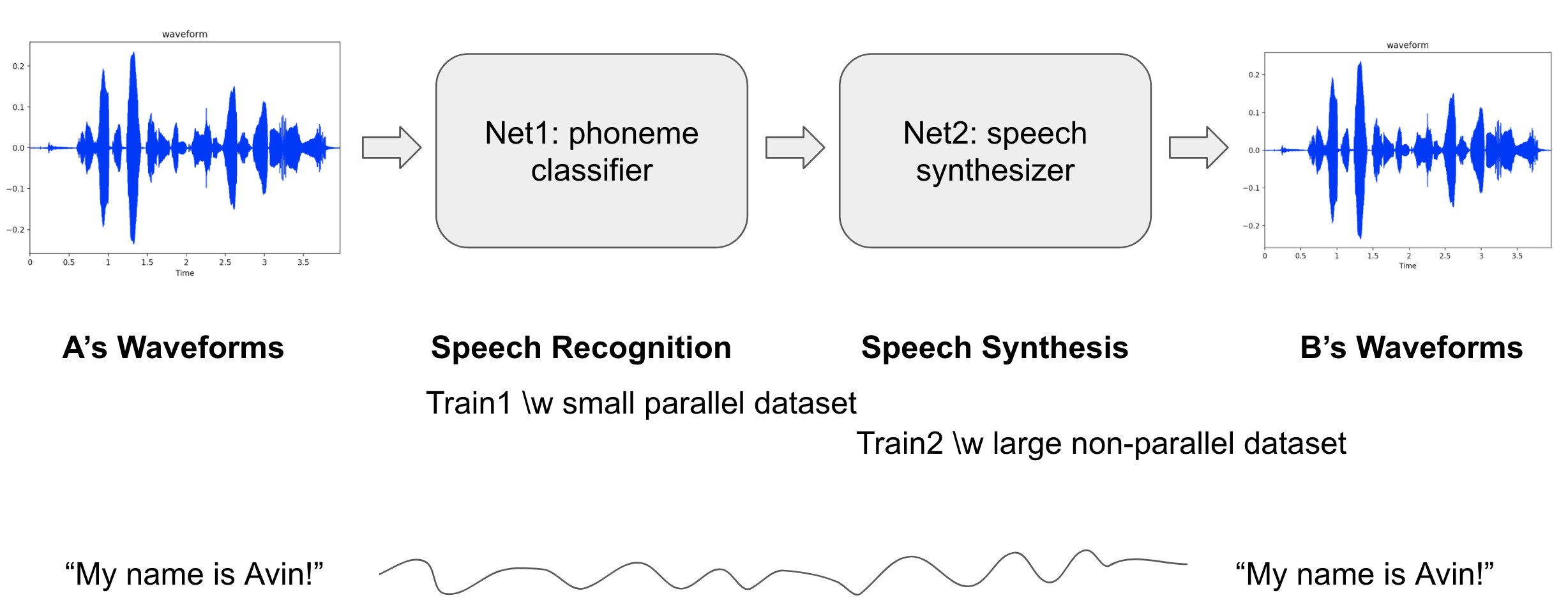
Архитектура модели состоит из двух модулей:
- Net1 (классификация фонем) классифицирует чьи-либо высказывания по одному из классов фонем на каждом временном шаге.
- Фонемы не зависят от говорящего, а волновые формы зависят.
- Net2 (синтез речи) синтезирует речь целевого говорящего из телефонов.
Мы применили модули CBHG (одномерная свёрточная банка + сеть с высокой пропускной способностью + двунаправленный GRU), которые упоминаются в Tacotron.
CBHG известен тем, что хорошо улавливает особенности последовательных данных.
Net1 — классификатор.
- Процесс: wav -> спектрограмма -> MFCCs -> распределение фонем.
- Net1 классифицирует спектрограмму по фонемам, состоящим из 60 английских фонем на каждом временном шаге.
- Для каждого временного шага входными данными является логарифмическая величина спектрограммы, а целью — распределение фонем.
- Целевая функция — потеря кросс-энтропии.
- Используется набор данных TIMIT.
- содержит 630 высказываний говорящих и соответствующие телефоны, которые произносят похожие предложения.
- Более 70 % точности теста.
Net2 — синтезатор.
Net2 содержит Net1 в качестве подсети.
- Процесс: net1 (wav -> спектрограмма -> MFCCs -> распределение фонем) -> спектрограмма -> wav
- Net2 синтезирует речи целевого говорящего.
- Входными и целевыми данными является набор высказываний целевого говорящего.
- Поскольку Net1 уже обучен на предыдущем этапе, оставшуюся часть следует обучать только на этом этапе.
- Потеря — ошибка реконструкции между входом и целью. (Расстояние L2)
- Наборы данных
- Target1 (анонимная женщина): набор данных Arctic (общедоступный)
- Target2 (Кейт Уинслет): более 2 часов предложений из аудиокниги, прочитанной ею (частный)
- Реконструкция Гриффина-Лима при обратном преобразовании wav из спектрограммы.
Реализация
Требования
- python 2.7
- tensorflow >= 1.1
- numpy >= 1.11.1
- librosa == 0.5.1
Настройки
- частота дискретизации: 16 000 Гц
- длина окна: 25 мс
- шаг: 5 мс
Процедура
- Фаза обучения: Net1 и Net2 следует обучать последовательно.
- Train1 (обучение Net1)
- Запустите
train1.py для обучения и eval1.py для тестирования.
- Train2 (обучение Net2)
- Запустите
train2.py для обучения и eval2.py для тестирования.
- Train2 следует обучать после завершения Train1!
- Конверсионная фаза: прямой проход к Net2
- Запустите
convert.py, чтобы получить образцы результатов.
- Проверьте аудиовкладку Tensorboard, чтобы прослушать образцы. Посмотрите на визуализацию распределения фонем на вкладке «Изображение» в Tensorboard.
- ось X представляет классы фонем, а ось Y — временные шаги;
- первый класс оси X означает тишину.
Советы (выводы, которые мы сделали из этого проекта)
- Длина окна и длина перехода должны быть достаточно малыми, чтобы вмещать только одну фонему.
- Очевидно, что частота дискретизации, длина окна и длина перехода должны совпадать в Net1 и Net2.
- Перед ISTFT (преобразование спектрограммы в форму волны) полезно для удаления шумов усилить предсказанную спектрограмму, применив коэффициент 1,0–2,0.
- Кажется, что применение температуры к softmax в Net1 не имеет большого смысла.
- На мой взгляд, точность Net1 (классификация фонем) не должна быть идеальной.
- Net2 может достичь почти оптимального результата, когда точность Net1 в некоторой степени верна.
Ссылки
- «Фонографические посториорграммы для много-к-одному преобразования голоса без параллельного обучения данным», Международная конференция IEEE по мультимедиа и экспо (ICME), 2016 г.
- «TACOTRON: К полностью автоматическому синтезу речи», представлено на Interspeech 2017.
Комментарии ( 0 )